
The numbers leave little room for debate: the majority of recruitment teams find it difficult to get their jobs up on Google, let alone optimized and ranked highly so that they actually move the needle on their hiring efforts.
So while Google for Jobs has quickly become a simple, intuitive, and widely used platform for job seekers to search through job posts, it’s ease-of-use is not something that’s mirrored by the employer experience.
The recruitment landscape is, to say the least, cluttered with jobs data. With over 11 million open jobs in the US alone, record high levels of employee turnover, and an endless list of job boards and career sites to search from, it’s become very difficult for recruitment teams to stay competitive. These factors have collectively increased pressure on employers to ensure they are not only providing an excellent application experience to job seekers, but also optimizing the channels where they are searching for jobs in the first place.
And, while today’s job seekers have the upper hand given the sustained trends of more open jobs, more new hires, and more employee turnover, the sheer volume of places to search for jobs confuses them. Many candidates spend hours applying to seemingly open positions only to find that the majority of the jobs they’re working on are expired or inaccurate. This has led to a focus on finding simple, intuitive, effective channels to access and apply to relevant jobs.
The current employment landscape was exactly what led Google to launch Google for Jobs, a one-stop shop for job seekers to use advanced search tools to find the positions that closely match their preferences, right from the place where they search for virtually everything else.
Yet while the Google job search function is positioned to dominate the online recruitment landscape, the platform is not without issues.
The majority of recruitment teams find it difficult to get their jobs up on Google, let alone optimized. The job posting interface is complex and difficult to understand, with far too many ranking signals to make sense of.
Much of this is due to the structured data (aka, schema) that adds a high level of complexity to Google for Jobs…but more on that later.
In this article, we dive deeper into why employers are struggling to make the most of the Google for Jobs platform and how their lives can be made easier.
Google for Jobs aggregates job postings from across the web, whether from small businesses or the massive career sites that host hundreds of thousands of job posts. It also means that job seekers can find employment without ever having to leave the place where they start their job searches.
A platform that leverages Google’s vast and powerful search tools (like location, company info, and reviews) is a no-brainer for recruiters to invest their time and energy in. But, as we’ve mentioned, getting jobs indexed and ranked highly on Google for Jobs is neither simple nor easy.
If, as an employer, you want to post a job on a platform like LinkedIn, it’s easy enough to figure out how to do it on your own. The interface is user-friendly and fairly straight forward.
But if you start exploring Google for Jobs because you want to reach more qualified candidates in the place where they do most of their searching, the first thing you’d likely notice is the complex job posting schema that you need to understand to post a job in the first place.
Google necessitates that you add HTML to the top of any job pages, meaning you’ll need fairly deep technical knowledge (or technical resources) to get your jobs up and ranking. This bears repeating: as a recruiter, you need fairly deep technical expertise just to get your jobs up on Google.
Unfortunately, making sense of the schema isn’t easy.
So what exactly does this whole ‘schema’ thing entail?
In general, structured data is any data that can be organized or given structure. When it comes to posting jobs on Google, things are no different.
To take advantage of Google for Jobs, job pages need to have structured data. Most notably, they need to incorporate elements and attributes about the jobs you want to post. Many of these elements and attributes are required (like the job title, description and location, company information, posting and expiration dates, and so on). Others elements and attributes, however, are optional (like the base salary and employment type). If you’re looking to explore these attributes, check out some job advertisements worth stealing from.
The following image provides a glimpse into Google for Jobs’ structured data requirements:
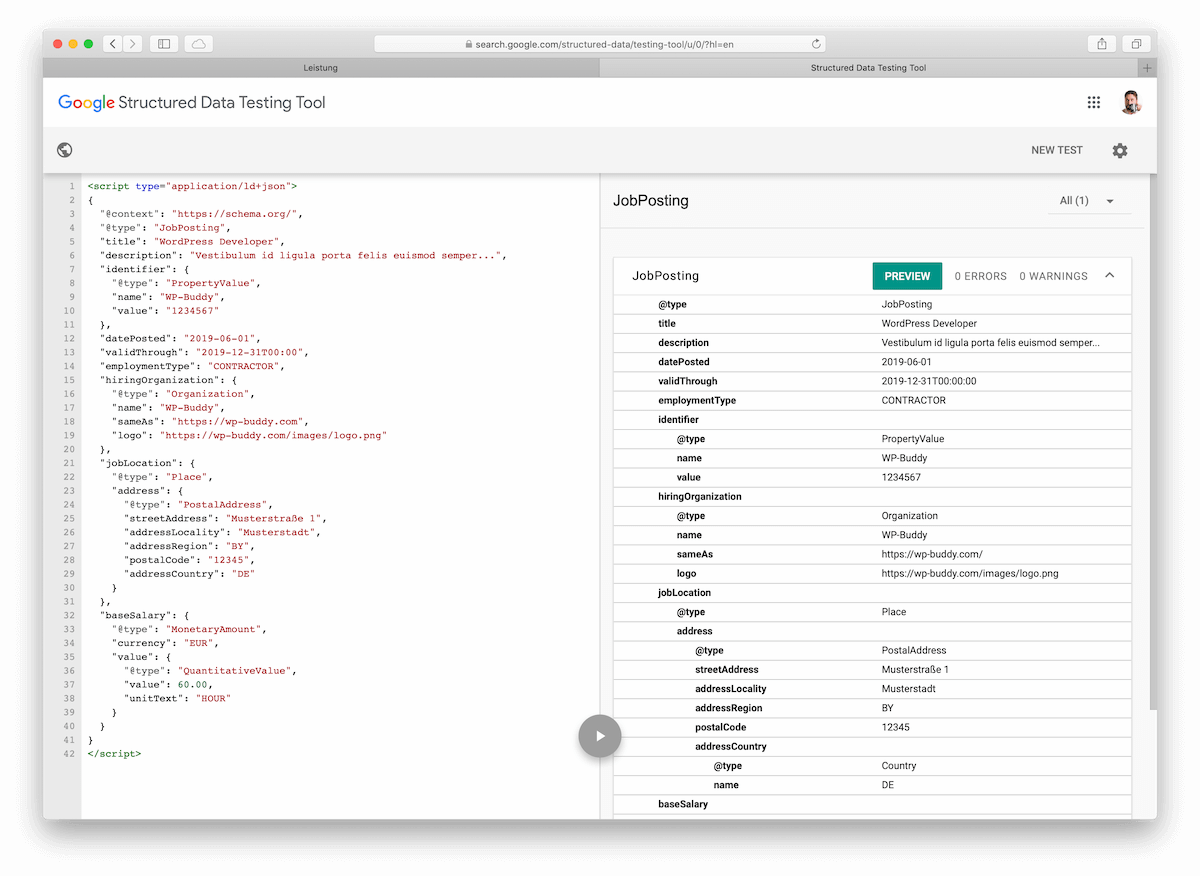
We know…it looks a bit scary.
These structured data requirements are Google’s way of ensuring that all the details that are most relevant for job seekers show up in job search results. They provide job seekers with the excellent user experience that they’ve come to expect from Google, and are one of the main reasons that the Google for Jobs platform is so incredible.
This power, however, doesn’t come without a cost. Employers are struggling to create this complex schema because they rarely have the necessary technical knowledge, or resources, required. They can’t make sense of Google’s HTML and JSON requirements by themselves. This is just the tip of the iceberg: because the code must be created and embedded on each job page individually, the process is very time-consuming even if you have technical resources dedicated to job posting and optimization.
Making sure that every single one of your job postings complies with a specified schema is a headache. Trying to do this manually is, as we mentioned, time-consuming and requires technical knowledge and resources that most recruiters simply don’t have.
While it’s possible to automate the whole job posting and optimization process on Google, it’s not easy. This is largely due to the unstructured nature of job posts. Virtually every job differs in form, structure, and content. This makes sense for a number of reasons, including:
Dealing with such diverse data structures, forms, and content is problematic. Traditional algorithms are unreliable to begin with. When they try to account for the complexity of vocabulary and structure used in job postings, things get even worse.
Given the latest developments in Artificial Intelligence (AI), the widespread adoption of technologies like ChatGPT, and improvements public perception of AI, the logical jump that many make when thinking about how to make Google for Jobs easier for employeres is applying AI.
AI is revolutionizing many industries, from design and manufacturing to marketing and sales, and job posting performance is no exception. Companies are working on Deep Learning and Machine Learning (ML) algorithms to automatically extract relevant job information and make jobs posting easier. This ML process, however, is often lengthy and complex.
It requires:

These factors make the tag prediction problem a complex one. But because there are such obvious benefits to solving it, many companies have tried.
While the problem is complex, it’s not impossible to solve. Developments in AI and ML have enabled companies to automatically scan job posts, identify the attributes that Google requires (in real time), and structure them appropriately. All without any human intervention.
These innovations required hundreds of engineers to diligently provide code, studies, labels and feedback tests. Platforms needed to be constantly tweaked and refined in a way that would enable employwers to quickly and directly publish job postings to Google for Jobs, as well as other search and social media platforms.
The result(s) for employers?
That’s right – with automation, Google for Jobs suddenly becomes a whole lot easier and more effective.
Getting Google for Jobs right can quickly become a full-time job. Let AI and automation check all the boxes for you.






